1University of California San Diego 2Hillbot
Accepted by SIGGRAPH Asia 2025








































































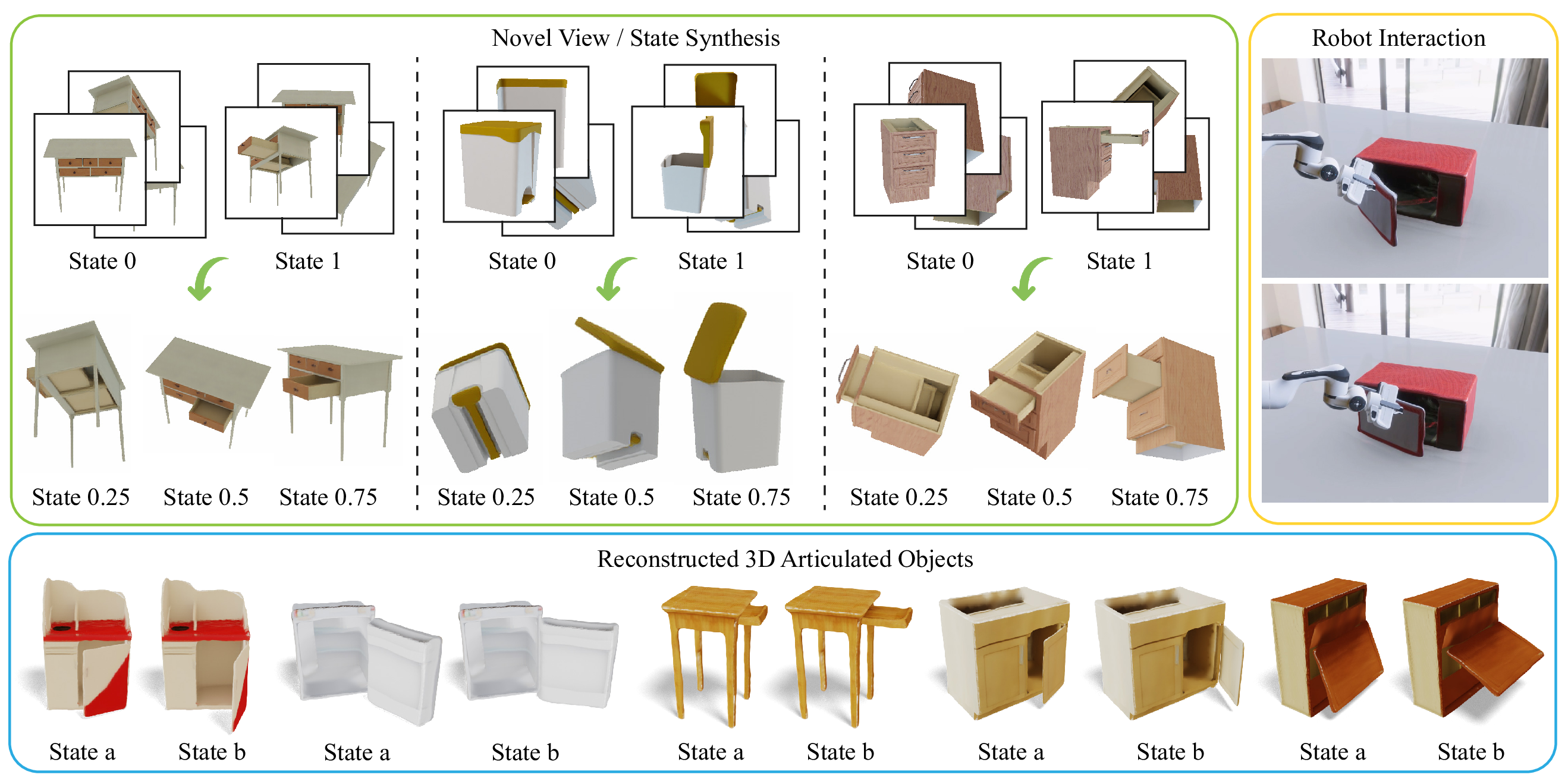
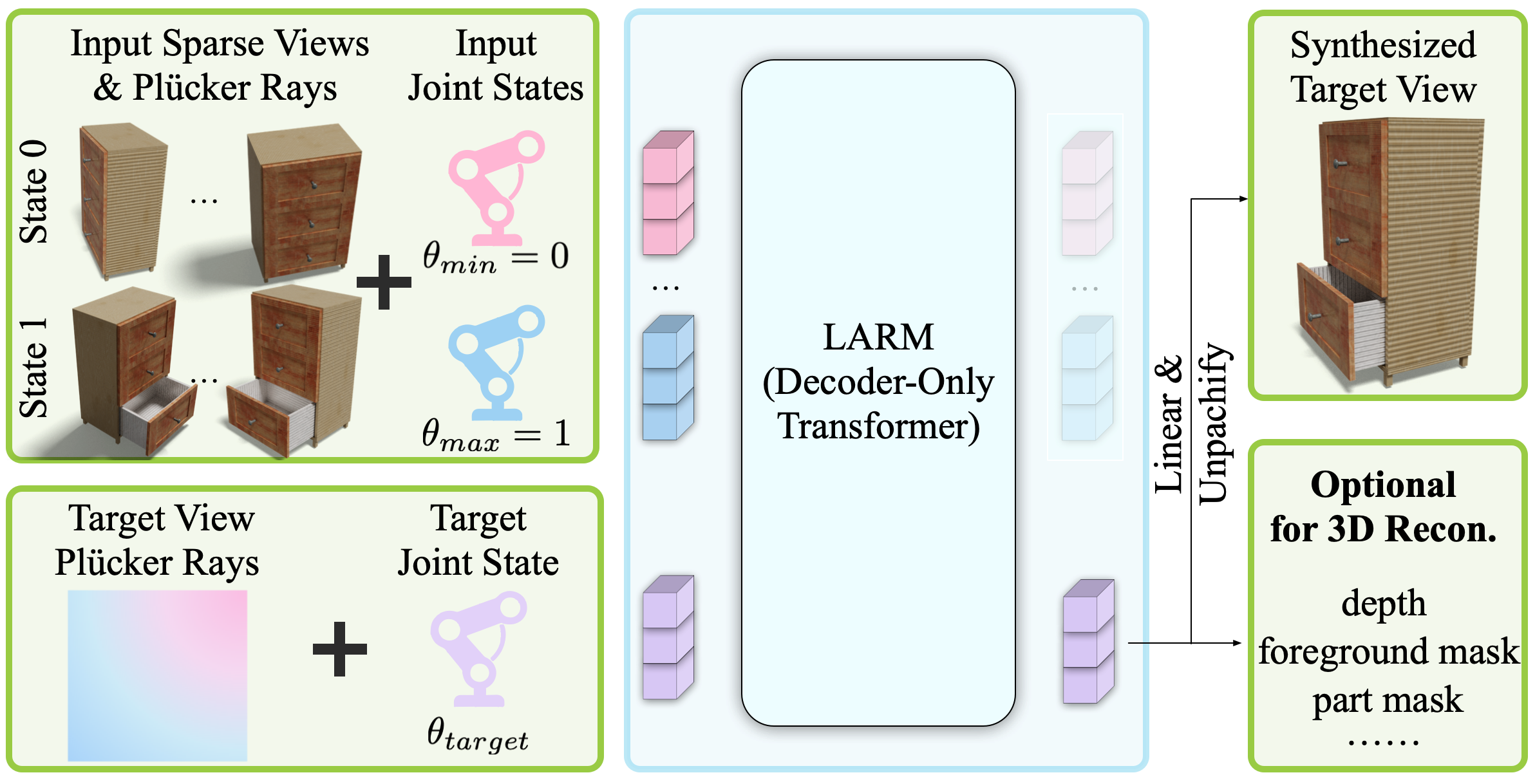
Modeling 3D articulated objects with realistic geometry, textures, and kinematics is essential for a wide range of applications. However, existing optimization-based reconstruction methods often require dense multi-view inputs and expensive per-instance optimization, limiting their scalability. Recent feedforward approaches offer faster alternatives but frequently produce coarse geometry, lack texture reconstruction, and rely on brittle, complex multi-stage pipelines. We introduce LARM, a unified feedforward framework that reconstructs 3D articulated objects from sparse-view images by jointly recovering detailed geometry, realistic textures, and accurate joint structures. LARM extends LVSM—a recent novel view synthesis (NVS) approach for static 3D objects—into the articulated setting by jointly reasoning over camera pose and articulation variation using a transformer-based architecture, enabling scalable and accurate novel view synthesis. In addition, LARM generates auxiliary outputs such as depth maps and part masks to facilitate explicit 3D mesh extraction and joint estimation. Our pipeline eliminates the need for dense supervision and supports high-fidelity reconstruction across diverse object categories. Extensive experiments demonstrate that LARM outperforms state-of-the-art methods in both novel view and state synthesis as well as 3D articulated object reconstruction, generating high-quality meshes that closely adhere to the input images.


@article{yuan2025larmlargearticulatedobjectreconstruction,
title={LARM: A Large Articulated-Object Reconstruction Model},
author={Yuan, Sylvia and Shi, Ruoxi and Wei, Xinyue and Zhang, Xiaoshuai and Su, Hao and Liu, Minghua},
journal={arXiv preprint arXiv:2511.11563},
year={2025},
}